Dany-William Tagne

I'm an AI Engineer specializing in deep learning and Generative AI, particularly in the use of Large LanguageModels (LLMs). A graduate of ESEO Paris, I have hands-on experience designing and building complex AIsystems, including agentic architectures and Retrieval-Augmented Generation (RAG) pipelines. My work includes model reconstruction, such as redesigning LoRA-based workflows, as well as developingrecommendation systems and handling complex data processing tasks. I'm deeply passionate about cutting-edge AI, and I actively explore emerging techniques through in-depth reading of AI research papers.
SoundMixAI is a smart application that I created that lets independent musicians, beatmakers, and home producers mix their tracks using natural language commands.
You can say:
"Balance the volume between all tracks"
"Apply a high-pass EQ to the vocals"
"Add delay to the guitar, but keep it short"
"Avoid frequency clashes between the kick and the bass"
And the AI:
Directly controls your DAW via API or scripting
Applies mixing effects and processes as requested
Leverages best-practice mixing knowledge (via a RAG system built from a curated PDF guide)
Can be supervised and corrected in real-time to improve results
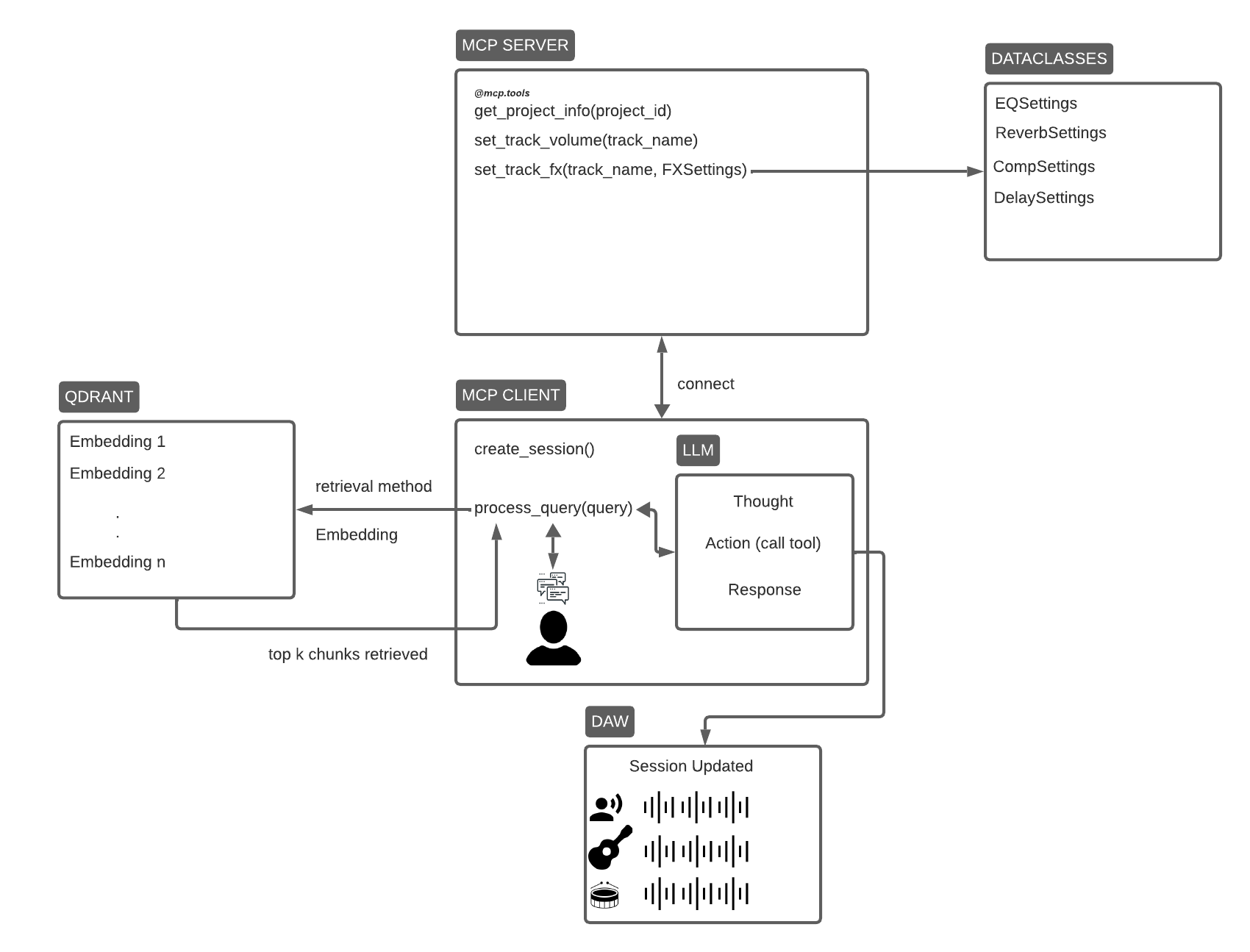
Stack & Architecture:
Ingestion & RAG → PDFs/Docs → FastEmbed → Qdrant (embeddings) → retrieval.
ODM Mongo (Python OOP) → stores documents, chunks, sessions, preferences.
Pipeline Orchestration → ZenML to track ingestion, embed, plan, exec.
Agent (Python3 + FastMCP + LLM) → interprets prompts, generates an ActionPlan JSON.
DAW Controller → applies the ActionPlan via API/scripting + feedback loop.
DEMO
Intelligent-ERP-Conversational-Agent
I built this chatbot to allow the user to interact with our ERP through textual instructions.
Example: “Create a quotation for client A with 3 products: A, B, C.”
It is integrated as a copilot directly within the user’s window.
The source code is private.
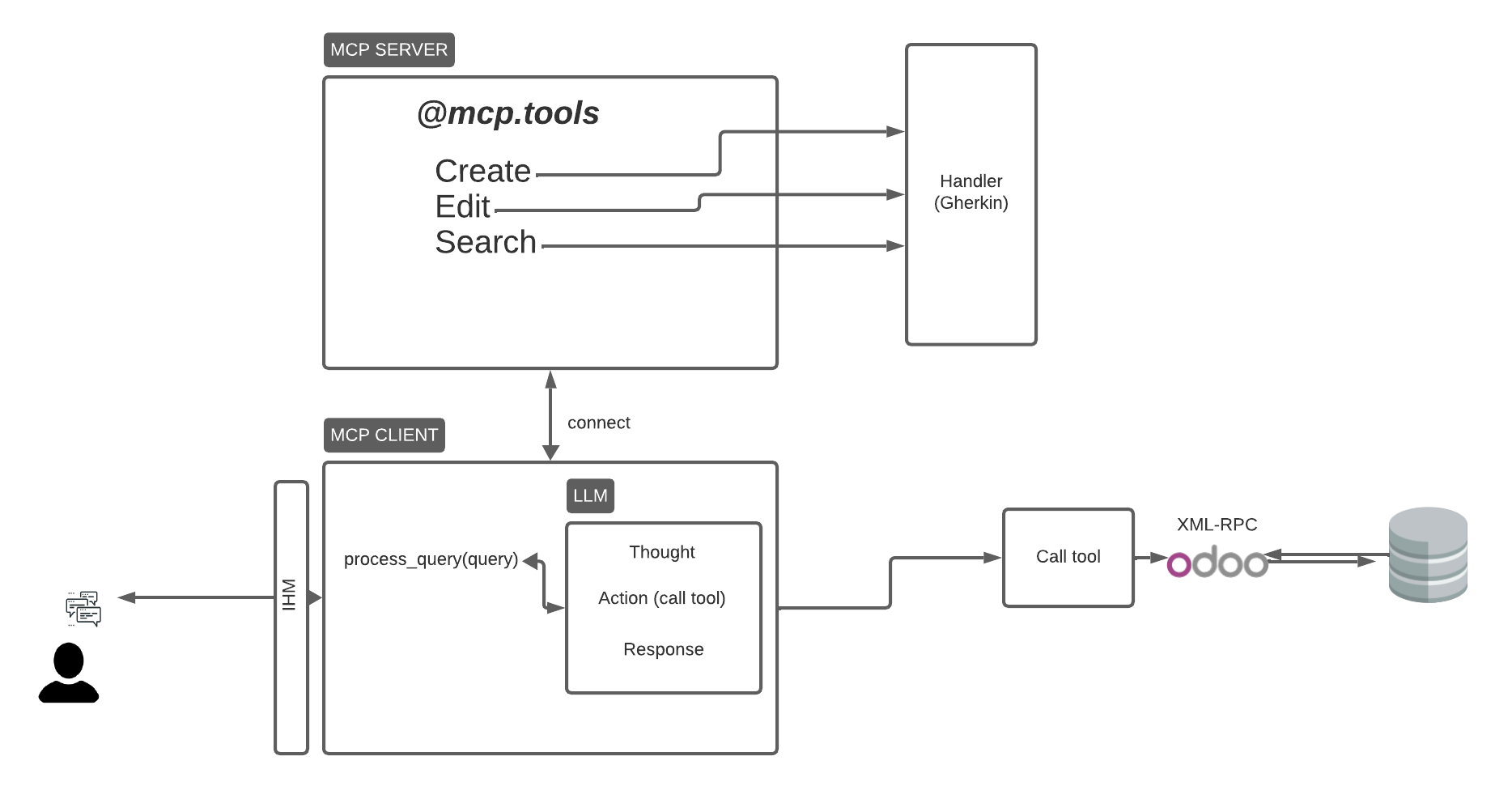
Stack & Architecture:
LLM Agent (LangChain) → interprets user instructions.
Custom Tools (Python) → wrap ERP business actions (e.g., create quotation).
MCP Architecture → standardize tools and ensure controlled execution.
Python ORM (SQLAlchemy, etc.) → secure interaction with the ERP database.
UI Integration → copilot embedded directly inside the ERP window.
LLM Fine Tuning
I built an end-to-end fine-tuning pipeline for transformer LLMs using the LoRA method, starting from raw text and finishing with an adapted model. The pipeline loads and preprocesses a custom dataset, chunking it into language-modeling sequences with inputs (x), shifted targets (y), and a mask to exclude padding from loss. I implemented a LoRA adapter that injects low-rank updates (matrices A and B) into selected transformer weights, drastically reducing trainable parameters while preserving capacity. Training uses a custom loop with batched dataloading, device moves (CPU/GPU), forward pass to logits, masked cross-entropy, gradient clipping for stability, optional mixed-precision (fp16) with gradient scaling, and running-loss tracking. I validated the approach on a corpus of Miyamoto Musashi’s writings to produce an AI that emulates his tone and philosophy, enabling responsive conversations in a Musashi-inspired voice.

Project SUMMARY & RAG CHAT
Features
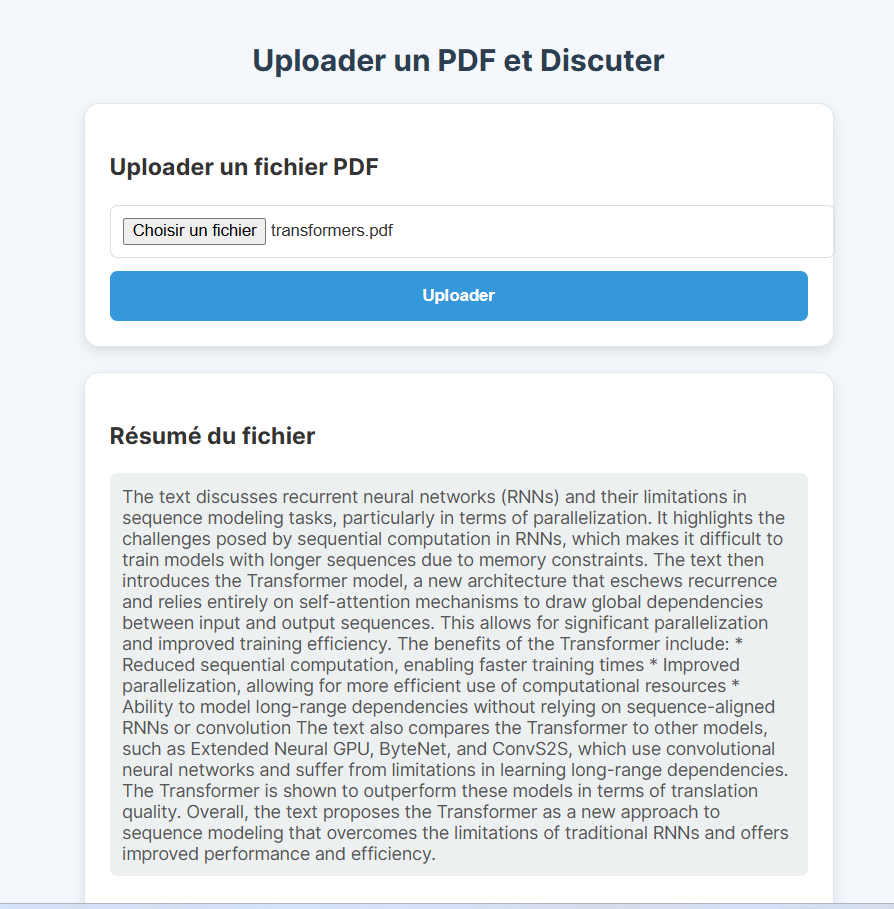
PDF Summarization: Upload a PDF, and the app will generate a concise summary of its content.
Ask Questions: After summarizing the document, you can ask the app questions related to the summary, and it will provide relevant answers.
Local Model: The app runs locally, ensuring privacy and fast responses.
Dockerized Environment: The entire system is containerized in Docker for easy deployment and setup.
Chroma Database: Chroma is used to store and retrieve embeddings of the documents for accurate similarity-based question answering.
Tech Stack
Python: The main programming language used for processing PDFs, generating embeddings, and handling the question-answering logic.
Docker: Used to containerize the app and all its dependencies.
Chroma DB: A vector database to store embeddings and documents for efficient retrieval and question answering.
Transformers: Pre-trained language models (e.g., GPT, BERT, etc.) used for text generation and summarization.
Flask (or any web framework of your choice): To create a simple web interface to interact with the app.